 |
Distributionally Robust Models with Parametric Likelihood Ratios
ICLR 2022 [abstract]
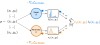
As machine learning models are deployed ever more broadly, it becomes increasingly important that they are not only able to perform well on their training distribution, but also yield accurate predictions when confronted with distribution shift. The Distributionally Robust Optimization (DRO) framework proposes to address this issue by training models to minimize their expected risk under a collection of distributions, to imitate test-time shifts. This is most commonly achieved by instance-level re-weighting of the training objective to emulate the likelihood ratio with possible test distributions, which allows for estimating their empirical risk via importance sampling (assuming that they are subpopulations of the training distribution). However, re-weighting schemes in the literature are usually limited due to the difficulty of keeping the optimization problem tractable and the complexity of enforcing normalization constraints. In this paper, we show that three simple ideas -- mini-batch level normalization, a KL penalty and simultaneous gradient updates -- allow us to train models with DRO using a broader class of parametric likelihood ratios. In a series of experiments on both image and text classification benchmarks, we find that models trained with the resulting parametric adversaries are consistently more robust to subpopulation shifts when compared to other DRO approaches, and that the method performs reliably well with little hyper-parameter tuning. |
 |
Balancing Average and Worst-case Accuracy in Multitask Learning
Preprint [abstract]
When training and evaluating machine learning models on a large number of tasks, it is important to not only look at average task accuracy -- which may be biased by easy or redundant tasks -- but also worst-case accuracy (i.e. the performance on the task with the lowest accuracy). In this work, we show how to use techniques from the distributionally robust optimization (DRO) literature to improve worst-case performance in multitask learning. We highlight several failure cases of DRO when applied off-the-shelf and present an improved method, Lookahead-DRO (L-DRO), which mitigates these issues. The core idea of L-DRO is to anticipate the interaction between tasks during training in order to choose a dynamic re-weighting of the various task losses, which will (i) lead to minimal worst-case loss and (ii) train on as many tasks as possible. After demonstrating the efficacy of L-DRO on a small controlled synthetic setting, we evaluate it on two realistic benchmarks: a multitask version of the CIFAR-100 image classification dataset and a large-scale multilingual language modeling experiment. Our empirical results show that L-DRO achieves a better trade-off between average and worst-case accuracy with little computational overhead compared to several strong baselines. |
 |
Should We Be Pre-training? An Argument for End-task Aware Training as an Alternative
ICLR 2022 [abstract]
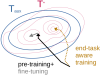
Pre-training, where models are trained on an auxiliary objective with abundant data before being fine-tuned on data from the downstream task, is now the dominant paradigm in NLP. In general, the pre-training step relies on little to no direct knowledge of the task on which the model will be fine-tuned, even when the end-task is known in advance. Our work challenges this status-quo of end-task agnostic pre-training. First, on three different low-resource NLP tasks from two domains, we demonstrate that multi-tasking the end-task and auxiliary objectives results in significantly better downstream task performance than the widely-used task-agnostic continued pre-training paradigm of Gururangan et al. (2020). We next introduce an online meta-learning algorithm that learns a set of multi-task weights to better balance among our multiple auxiliary objectives, achieving further improvements on end task performance and data efficiency. |
 |
Learning Neural Models for Natural Language Processing in the Face of Distributional Shift
PhD Dissertation [abstract]
The dominating NLP paradigm of training a strong neural predictor to perform one task on a specific dataset has led to state-of-the-art performance in a variety of applications (eg. sentiment classification, span-prediction based question answering or machine translation). However, it builds upon the assumption that the data distribution is stationary, ie. that the data is sampled from a fixed distribution both at training and test time. This way of training is inconsistent with how we as humans are able to learn from and operate within a constantly changing stream of information. Moreover, it is ill-adapted to real-world use cases where the data distribution is expected to shift over the course of a model's lifetime. The first goal of this thesis is to characterize the different forms this shift can take in the context of natural language processing, and propose benchmarks and evaluation metrics to measure its effect on current deep learning architectures. We then proceed to take steps to mitigate the effect of distributional shift on NLP models. To this end, we develop methods based on parametric reformulations of the distributionally robust optimization framework. Empirically, we demonstrate that these approaches yield more robust models as demonstrated on a selection of realistic problems. In the third and final part of this thesis, we explore ways of efficiently adapting existing models to new domains or tasks. Our contribution to this topic takes inspiration from information geometry to derive a new gradient update rule which alleviate catastrophic forgetting issues during adaptation. |
 |
Examining and Combating Spurious Features under Distribution Shift
ICML 2021 [abstract]
A central goal of machine learning is to learn robust representations that capture the causal relationship between inputs features and output labels. However, minimizing empirical risk over finite or biased datasets often results in models latching on to spurious correlations between the training input/output pairs that are not fundamental to the problem at hand. In this paper, we define and analyze robust and spurious representations using the information-theoretic concept of minimal sufficient statistics. We prove that even when there is only bias of the input distribution (i.e. covariate shift), models can still pick up spurious features from their training data. Group distributionally robust optimization (DRO) provides an effective tool to alleviate covariate shift by minimizing the worst-case training loss over a set of pre-defined groups. Inspired by our analysis, we demonstrate that group DRO can fail when groups do not directly account for various spurious correlations that occur in the data. To address this, we further propose to minimize the worst-case losses over a more flexible set of distributions that are defined on the joint distribution of groups and instances, instead of treating each group as a whole at optimization time. Through extensive experiments on one image and two language tasks, we show that our model is significantly more robust than comparable baselines under various partitions. |
| Modeling the Second Player in Distributionally Robust Optimization
ICLR 2021 [abstract]
Distributionally robust optimization (DRO) provides a framework for training machine learning models that are able to perform well on a collection of related data distributions (the "uncertainty set"). This is done by solving a min-max game: the model is trained to minimize its maximum expected loss among all distributions in the uncertainty set. While careful design of the uncertainty set is critical to the success of the DRO procedure, previous work has been limited to relatively simple alternatives that keep the min-max optimization problem exactly tractable, such as -divergence balls. In this paper, we argue instead for the use of neural generative models to characterize the worst-case distribution, allowing for more flexible and problem-specific selection of the uncertainty set. However, while simple conceptually, this approach poses a number of implementation and optimization challenges. To circumvent these issues, we propose a relaxation of the KL-constrained inner maximization objective that makes the DRO problem more amenable to gradient-based optimization of large scale generative models, and develop model selection heuristics to guide hyper-parameter search. On both toy settings and realistic NLP tasks, we find that the proposed approach yields models that are more robust than comparable baselines. |
 |
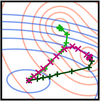
Findings of the WMT 2020 Shared Task on Machine Translation Robustness
WMT 2020 [abstract]
We report the findings of the second edition of the shared task on improving robustness in Machine Translation (MT). The task aims to test current machine translation systems in their ability to handle challenges facing MT models to be deployed in the real world, including domain diversity and non-standard texts common in user generated content, especially in social media. We cover two language pairs–English-German and English-Japanese and provide test sets in zero-shot and few-shot variants. Participating systems are evaluated both automatically and manually, with an additional human evaluation for "catastrophic errors". We received 59 submissions by 11 participating teams from a variety of types of institutions. |
 |
Regularizing Trajectories to Mitigate Catastrophic Forgetting
Arxiv [abstract]
Regularization-based continual learning approaches generally prevent catastrophic forgetting by augmenting the training loss with an auxiliary objective. However in most practical optimization scenarios with noisy data and/or gradients, it is possible that stochastic gradient descent can inadvertently change critical parameters. In this paper, we argue for the importance of regularizing optimization trajectories directly. We derive a new co-natural gradient update rule for continual learning whereby the new task gradients are preconditioned with the empirical Fisher information of previously learnt tasks. We show that using the co-natural gradient systematically reduces forgetting in continual learning. Moreover, it helps combat overfitting when learning a new task in a low resource scenario. |
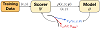 |
Optimizing Data Usage via Differentiable Rewards
ICML 2020 [abstract]
To acquire a new skill, humans learn better and faster if a tutor, based on their current knowledge level, informs them of how much attention they should pay to particular content or practice problems. Similarly, a machine learning model could potentially be trained better with a scorer that 'adapts' to its current learning state and estimates the importance of each training data instance. Training such an adaptive scorer efficiently is a challenging problem; in order to precisely quantify the effect of a data instance at a given time during the training, it is typically necessary to first complete the entire training process. To efficiently optimize data usage, we propose a reinforcement learning approach called Differentiable Data Selection (DDS). In DDS, we formulate a scorer network as a learnable function of the training data, which can be efficiently updated along with the main model being trained. Specifically, DDS updates the scorer with an intuitive reward signal: it should up-weigh the data that has a similar gradient with a dev set upon which we would finally like to perform well. Without significant computing overhead, DDS delivers strong and consistent improvements over several strong baselines on two very different tasks of machine translation and image classification. |
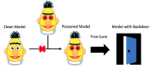 |
Weight Poisoning Attacks on Pre-trained Models
ACL 2020 [abstract]
Recently, NLP has seen a surge in the usage of large pre-trained models. Users download weights of models pre-trained on large datasets, then fine-tune the weights on a task of their choice. This raises the question of whether downloading untrusted pre-trained weights can pose a security threat. In this paper, we show that it is possible to construct ``weight poisoning'' attacks where pre-trained weights are injected with vulnerabilities that expose ``backdoors'' after fine-tuning, enabling the attacker to manipulate the model prediction simply by injecting an arbitrary keyword. We show that by applying a regularization method, which we call RIPPLe, and an initialization procedure, which we call Embedding Surgery, such attacks are possible even with limited knowledge of the dataset and fine-tuning procedure. Our experiments on sentiment classification, toxicity detection, and spam detection show that this attack is widely applicable and poses a serious threat. Finally, we outline practical defenses against such attacks. Code to reproduce our experiments is available at https://github.com/neulab/RIPPLe/. |
 |
Are Sixteen Heads Really Better than One?
NeurIPS 2019 [abstract]
Attention is a powerful and ubiquitous mechanism for allowing neural models to focus on particular salient pieces of information by taking their weighted average when making predictions. In particular, multi-headed attention is a driving force behind many recent state-of-the-art NLP models such as Transformer-based MT models and BERT. These models apply multiple attention mechanisms in parallel, with each attention "head" potentially focusing on different parts of the input, which makes it possible to express sophisticated functions beyond the simple weighted average. In this paper we make the surprising observation that even if models have been trained using multiple heads, in practice, a large percentage of attention heads can be removed at test time without significantly impacting performance. In fact, some layers can even be reduced to a single head. We further examine greedy algorithms for pruning down models, and the potential speed, memory efficiency, and accuracy improvements obtainable therefrom. Finally, we analyze the results with respect to which parts of the model are more reliant on having multiple heads, and provide precursory evidence that training dynamics play a role in the gains provided by multi-head attention. |
 |
Findings of the First Shared Task on Machine Translation Robustness
WMT 2019 [abstract]
We share the findings of the first shared task on improving robustness of Machine Translation (MT). The task provides a testbed representing challenges facing MT models deployed in the real world, and facilitates new approaches to improve models; robustness to noisy input and domain mismatch. We focus on two language pairs (English-French and English-Japanese), and the submitted systems are evaluated on a blind test set consisting of noisy comments on Reddit and professionally sourced translations. As a new task, we received 23 submissions by 11 participating teams from universities, companies, national labs, etc. All submitted systems achieved large improvements over baselines, with the best improvement having +22.33 BLEU. We evaluated submissions by both human judgment and automatic evaluation (BLEU), which shows high correlations (Pearson's r = 0.94 and 0.95). Furthermore, we conducted a qualitative analysis of the submitted systems using compare-mt, which revealed their salient differences in handling challenges in this task. Such analysis provides additional insights when there is occasional disagreement between human judgment and BLEU, e.g. systems better at producing colloquial expressions received higher score from human judgment. |
 |
compare-mt: A Tool for Holistic Comparison of Language Generation Systems
NAACL 2019 demo [abstract]
In this paper, we describe compare-mt, a tool for holistic analysis and comparison of the results of systems for language generation tasks such as machine translation. The main goal of the tool is to give the user a high-level and coherent view of the salient differences between systems that can then be used to guide further analysis or system improvement. It implements a number of tools to do so, such as analysis of accuracy of generation of particular types of words, bucketed histograms of sentence accuracies or counts based on salient characteristics, and extraction of characteristic n-grams for each system. It also has a number of advanced features such as use of linguistic labels, source side data, or comparison of log likelihoods for probabilistic models, and also aims to be easily extensible by users to new types of analysis. The code is available at this https URL. |
 |
On Evaluation of Adversarial Perturbations for Sequence-to-Sequence Models
NAACL 2019 [abstract]
Adversarial examples --- perturbations to the input of a model that elicit large changes in the output --- have been shown to be an effective way of assessing the robustness of sequence-to-sequence (seq2seq) models. However, these perturbations only indicate weaknesses in the model if they do not change the input so significantly that it legitimately results in changes in the expected output. This fact has largely been ignored in the evaluations of the growing body of related literature. Using the example of untargeted attacks on machine translation (MT), we propose a new evaluation framework for adversarial attacks on seq2seq models that takes the semantic equivalence of the pre- and post-perturbation input into account. Using this framework, we demonstrate that existing methods may not preserve meaning in general, breaking the aforementioned assumption that source side perturbations should not result in changes in the expected output. We further use this framework to demonstrate that adding additional constraints on attacks allows for adversarial perturbations that are more meaning-preserving, but nonetheless largely change the output sequence. Finally, we show that performing untargeted adversarial training with meaning-preserving attacks is beneficial to the model in terms of adversarial robustness, without hurting test performance. A toolkit implementing our evaluation framework is released at this https URL. |
 |
MTNT: A Testbed for Machine Translation of Noisy Text
EMNLP 2018 [abstract]
Noisy or non-standard input text can cause disastrous mistranslations in most modern Machine Translation (MT) systems, and there has been growing research interest in creating noise-robust MT systems. However, as of yet there are no publicly available parallel corpora of with naturally occurring noisy inputs and translations, and thus previous work has resorted to evaluating on synthetically created datasets. In this paper, we propose a benchmark dataset for Machine Translation of Noisy Text (MTNT), consisting of noisy comments on Reddit (www.reddit.com) and professionally sourced translations. We commissioned translations of English comments into French and Japanese, as well as French and Japanese comments into English, on the order of 7k-37k sentences per language pair. We qualitatively and quantitatively examine the types of noise included in this dataset, then demonstrate that existing MT models fail badly on a number of noise-related phenomena, even after performing adaptation on a small training set of in-domain data. This indicates that this dataset can provide an attractive testbed for methods tailored to handling noisy text in MT. The data is publicly available at www.cs.cmu.edu/~pmichel1/mtnt/. |
 |
Extreme Adaptation for Personalized Neural Machine Translation
ACL 2018 [abstract]
Every person speaks or writes their own flavor of their native language, influenced by a number of factors: the content they tend to talk about, their gender, their social status, or their geographical origin. When attempting to perform Machine Translation (MT), these variations have a significant effect on how the system should perform translation, but this is not captured well by standard one-size-fits-all models. In this paper, we propose a simple and parameter-efficient adaptation technique that only requires adapting the bias of the output softmax to each particular user of the MT system, either directly or through a factored approximation. Experiments on TED talks in three languages demonstrate improvements in translation accuracy, and better reflection of speaker traits in the target text. |
 |
DyNet: The Dynamic Neural Network Toolkit
Arxiv [abstract]
We describe DyNet, a toolkit for implementing neural network models based on dynamic declaration of network structure. In the static declaration strategy that is used in toolkits like Theano, CNTK, and TensorFlow, the user first defines a computation graph (a symbolic representation of the computation), and then examples are fed into an engine that executes this computation and computes its derivatives. In DyNet's dynamic declaration strategy, computation graph construction is mostly transparent, being implicitly constructed by executing procedural code that computes the network outputs, and the user is free to use different network structures for each input. Dynamic declaration thus facilitates the implementation of more complicated network architectures, and DyNet is specifically designed to allow users to implement their models in a way that is idiomatic in their preferred programming language (C++ or Python). One challenge with dynamic declaration is that because the symbolic computation graph is defined anew for every training example, its construction must have low overhead. To achieve this, DyNet has an optimized C++ backend and lightweight graph representation. Experiments show that DyNet's speeds are faster than or comparable with static declaration toolkits, and significantly faster than Chainer, another dynamic declaration toolkit. DyNet is released open-source under the Apache 2.0 license and available at this http URL |
 |
Does the Geometry of Word Embeddings Help Document Classification? A Case Study on Persistent Homology Based Representations ACL Repl4NLP Workshop 2017 [abstract]
We investigate the pertinence of methods from algebraic topology for text data analysis. These methods enable the development of mathematically-principled isometric-invariant mappings from a set of vectors to a document embedding, which is stable with respect to the geometry of the document in the selected metric space. In this work, we evaluate the utility of these topology-based document representations in traditional NLP tasks, specifically document clustering and sentiment classification. We find that the embeddings do not benefit text analysis. In fact, performance is worse than simple techniques like tf-idf, indicating that the geometry of the document does not provide enough variability for classification on the basis of topic or sentiment in the chosen datasets. |
 |
Blind phoneme segmentation with temporal prediction errors
ACL SRW 2017 [abstract]
Phonemic segmentation of speech is a critical step of speech recognition systems. We propose a novel unsupervised algorithm based on sequence prediction models such as Markov chains and recurrent neural network. Our approach consists in analyzing the error profile of a model trained to predict speech features frame-by-frame. Specifically, we try to learn the dynamics of speech in the MFCC space and hypothesize boundaries from local maxima in the prediction error. We evaluate our system on the TIMIT dataset, with improvements over similar methods. |